Optional features and Measurements¶
These are some measurements, which were done with the program on version 0.4.0, to get a basic overview of the capabilities and limitations so far.
Test with table¶
Data-input¶
The test-data were a CSV-file with one column for input and one for output with
- 100 times input 0 and desired output 0.0
- 100 times input 80 and desired output 1.0
- 100 times input 30 and desired output 0.5
- 100 times input 10 and desired output 0.75
- 100 times input 0 and desired output 0.0
Graphical the desired function to learn looks like this:
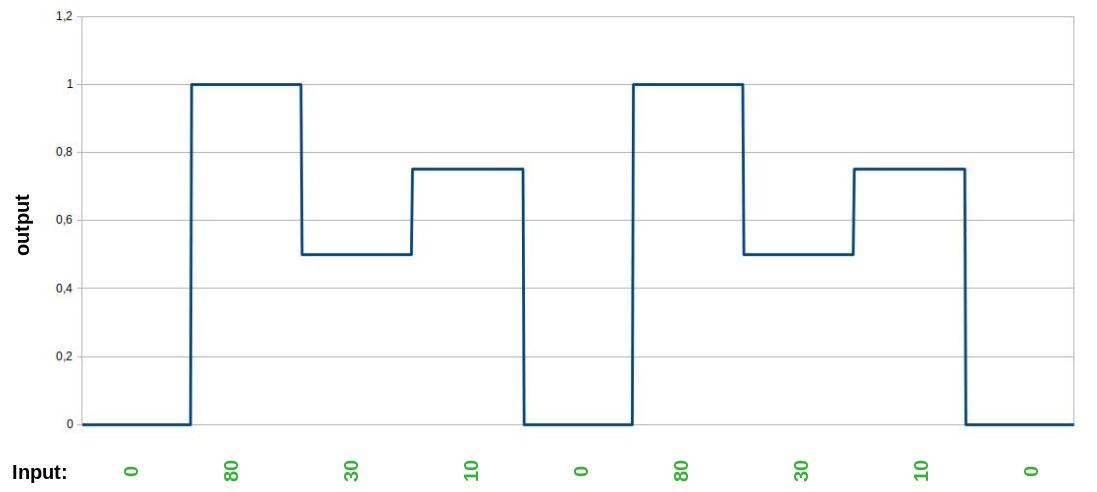
This is a very constructed scenario, so it is may be not the optimal case for testing the features.
Cluster-template¶
To define the cluster the following cluster-template was used:
version: 1
settings:
neuron_cooldown: 100000000000.0
refractory_time: 1
max_connection_distance: 1
enable_reduction: false
bricks:
1,1,1
input: test_input
number_of_neurons: 25
2,1,1
number_of_neurons: 128
3,1,1
number_of_neurons: 128
4,1,1
output: test_output
number_of_neurons: 5
Data-processing¶
Training on a CSV-file at the moment looks like this:
...
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ]
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ]
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ]
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ]
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 80 ]
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 80, 80 ]
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 80, 80, 80 ]
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 80, 80, 80, 80 ]
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 80, 80, 80, 80, 80 ]
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 80, 80, 80, 80, 80, 80 ]
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 80, 80, 80, 80, 80, 80, 80 ]
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 80, 80, 80, 80, 80, 80, 80, 80 ]
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 80, 80, 80, 80, 80, 80, 80, 80, 80 ]
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80 ]
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80 ]
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80 ]
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80 ]
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80 ]
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80 ]
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80 ]
[ 0, 0, 0, 0, 0, 0, 0, 0, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80 ]
[ 0, 0, 0, 0, 0, 0, 0, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80 ]
[ 0, 0, 0, 0, 0, 0, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80 ]
[ 0, 0, 0, 0, 0, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80 ]
[ 0, 0, 0, 0, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80 ]
[ 0, 0, 0, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80 ]
[ 0, 0, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80 ]
[ 0, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80 ]
[ 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80 ]
[ 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80 ]
[ 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80 ]
[ 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80 ]
[ 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80 ]
...
It maps the inputs of the input-brick on the beginning of the given data and with each cycle it moves one forward. For the output to train it is the same.
Results¶
The following shows the results with different options. On the left side the output is shown for the same input, while training. On the right side of the diagrams there are the real test-values. Green are the values, which were also in the training-dataset and red are the unknow inputs with the output, coming from the neural network for these inputs. All diagrams are showing the average of 10 measurements.
Normal¶
In this case, only the default-values of the settings-block were used.
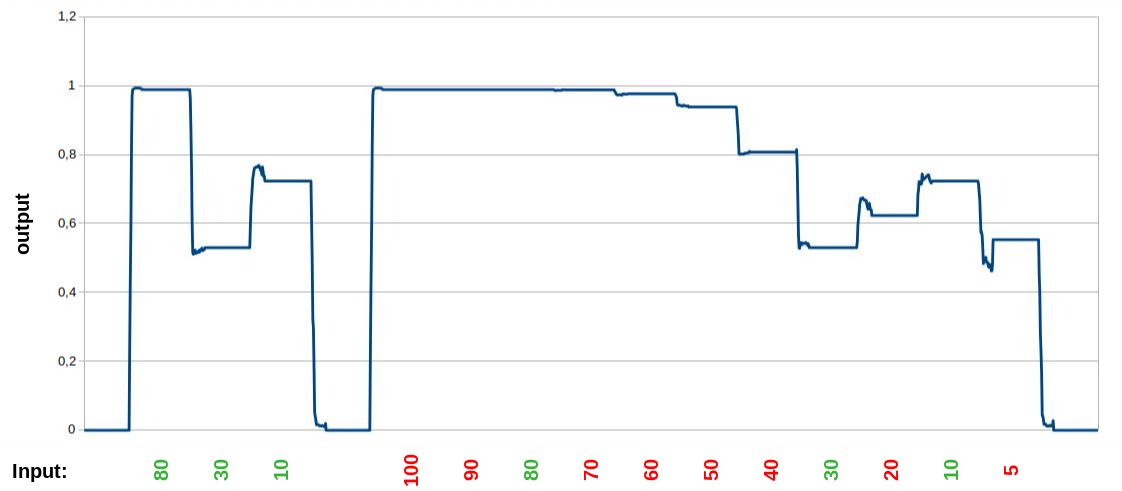
The left part for the trained inputs are showing nearly the exact output, like trained. The right side shows a really good interpolation for unknown (red) input-values. Even the 100, which is above the trained maximum, doesn't break the result and the cluster handle the value, like the maximum, which it has learned while training.
With different settings¶
Used were the settings-options within the cluster-template to modify the behavior of the cluster.
-
Modified neuron-cooldown and refractory-time
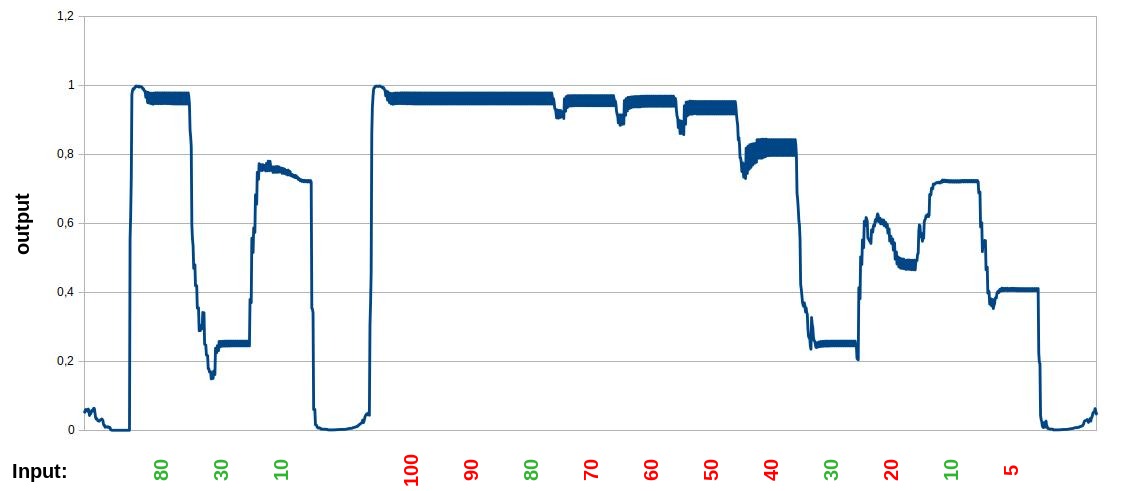
-
Modified connection-distance
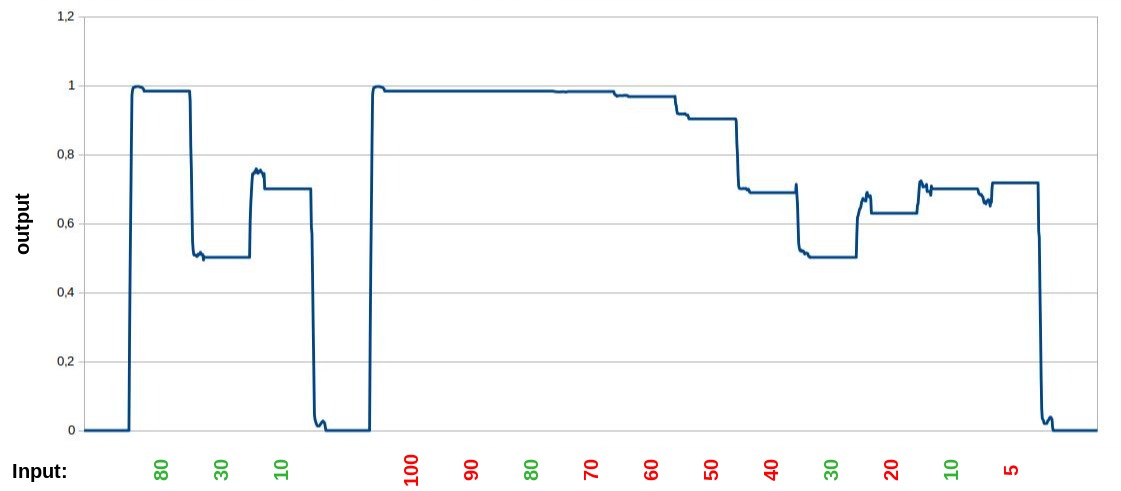
-
Modified neuron-cooldown, refractory-time and connection-distance
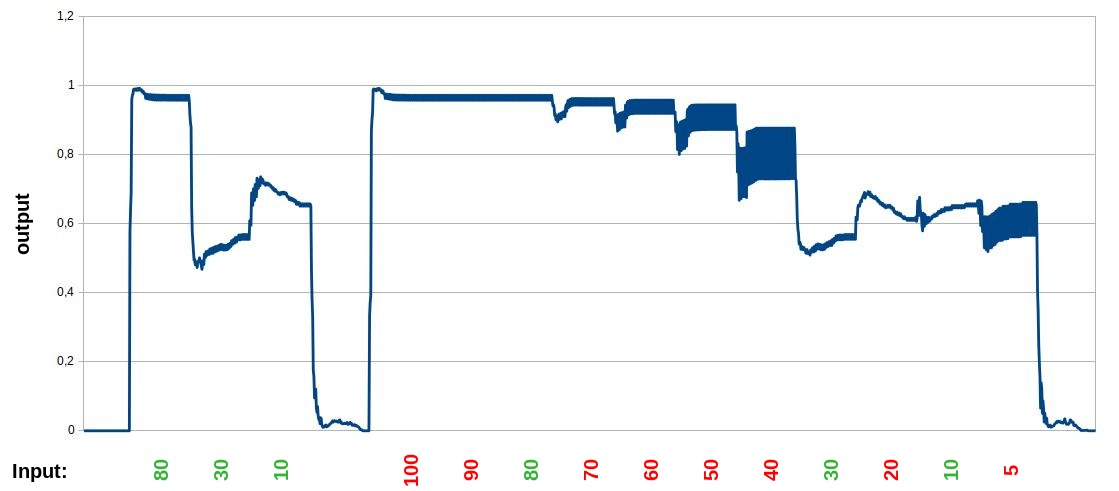
The output is still similar, like in the normal version, so it doesn't break the result, but the output is not better compared to the normal version. The thicker lines showing the the places, where the output spikes and switch between two values. Maybe this example here is too small and/or too artificial constructed to bring some advantages, but it is interesting to see, that in the unknown interpolated sections the spikes are much bigger.
Info
These examples will be updated, when a more optimal test-case was found. It is only the current state of evaluation.
Reduction¶
With default-values, but enabled reduction-process the diagram looks nearly the same like the normal version without reduction.
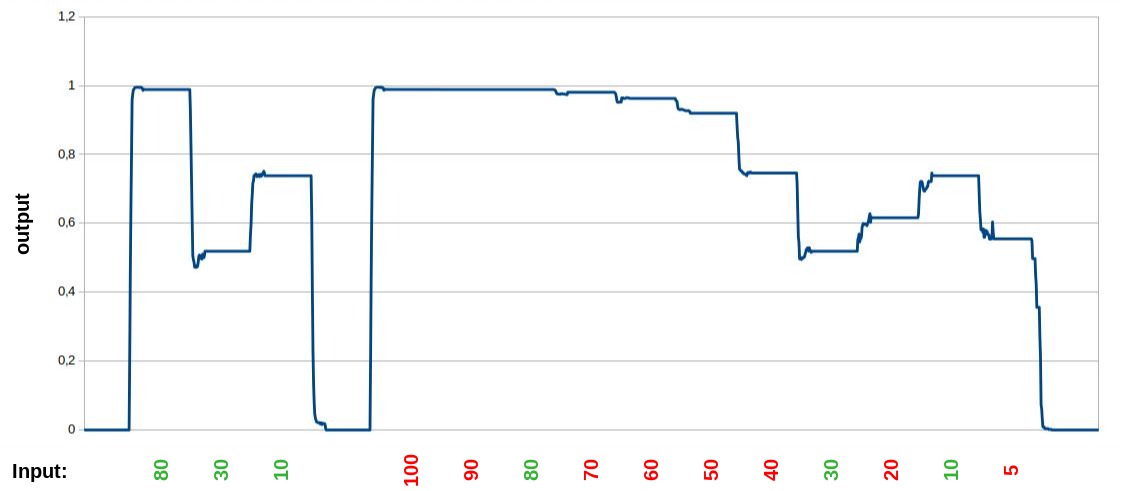
Because there are only 4 different input-values in the test, which are used over and over again, a big difference also wouldn't be expected, but the transitions between the different input-values are looking a bit smother compared to the other version.
MNIST-Test¶
Because the constructed case above doesn't show much measurable impact, the reduction-process was also tested with the MNIST-dataset.
Cluster-template¶
Here the used cluster-template for this test:
version: 1
settings:
enable_reduction: false
bricks:
1,1,1
input: test_input
number_of_neurons: 784
2,1,1
number_of_neurons: 400
3,1,1
output: test_output
number_of_neurons: 10
Reduction¶
The following shows the impact of the reduction on the cluster-size. Here the number of synapses between the neurons are counted:
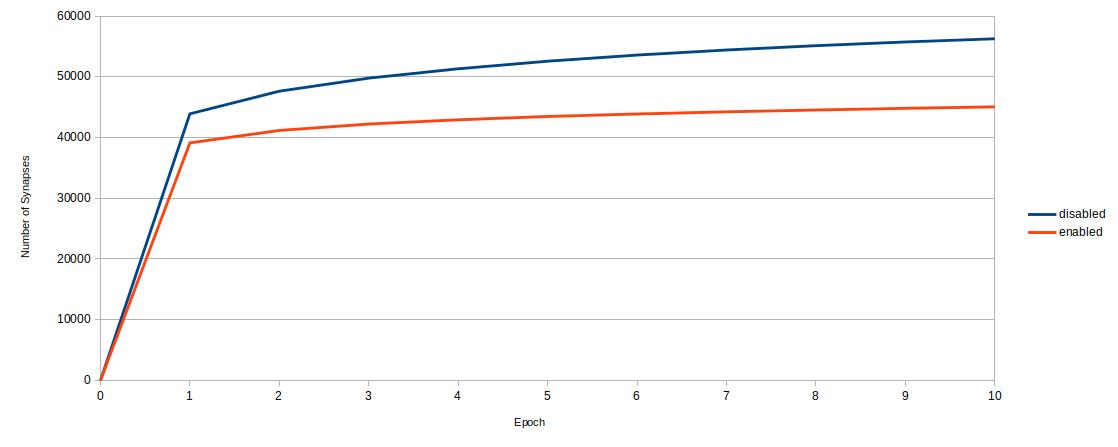
It shows the expected result, that the reduction-process reduce the number of synapses by removed them, which are not used often enough, which can have quite a bit impact on the size of the cluster.
On the other hand this has also impact on the accuracy of the result:
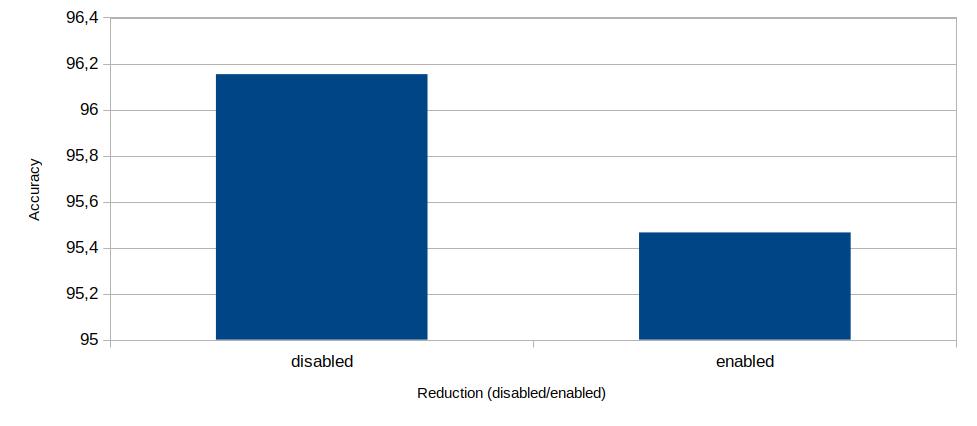
It shows, that the reduction also also impact on the output by reducting the accuracy in this test by 0,68% but in exchange it reduce the cluster-size by 20%.